シンセカイテクノロジーズの「MURA」というコミュニティサービスを、ゼロから作り替えました。試算では180人月かかるはずのものを、数ヶ月で出して、リリース初日に過去の月間売上の記録を超えました。企画統括の三浦慶介さんがこの再構築について書いた記事に出てくる「Y氏」である吉田が、ここで制作の秘密の裏側を残そうと思います。
それと「どうやってそんなに速く作れたんですか」とよく聞かれます。もちろんAIをフル稼働させているのですが、大切なのはそれをどう使うか。速く動かすための工夫もあって、それは記事の中で具体的に書いていくのですが、いちばん気にしているポイントとしては、判断までの時間と、判断そのものの時間を、両方をできるだけ短くすることです。
やったことのほとんどが、この判断系の2つに紐づいています。今日はそれを、これを読んでいるみなさんでも再現できる形で書きます。どこが真似できて、どこが真似しにくいのかも、書きわけていこうと思います。
僕はコードを1行も読まずに作った
まず最初に、いちばん変なところを書きます。このMURAの開発において、開発者である僕はコードを1行も読んでいません。リリースした今も、読んでいません。コードを書いたのはAIで、僕がやったのは、何を作るかを決めて、出てきたものを判断して、次の指示を出すこと、それだけをやりました。
企画のメンバーからは、「AIがチャット欄の返答で出してくる、あのプログラムらしきものを見ているなら、もうコードを読んでいるのと同じだ」と言われたことがあります。でも僕の感覚では、あれはコードを読んだことにはなっておらず、設計を読んだわけでも、ソースを追ったわけでもなく、判断の材料を見ていただけです。
この記事に出てくる、土台を何度も立て直した話も、プルリクをAIレビューでマージした話も、僕がコードを書いたり読んだりした話ではありません。全部、判断と指示でやっています。そう考えると、僕の仕事はほぼ判断だけだったのかもしれません。判断までの時間を短くすることが、そのまま全体進行が短くなる、つまり生産性の向上につながると考えています。
余談ですが、モックと改善要望をベースに作っていたので、実装している僕自身が、その機能がちゃんと動いていることを知らない、ということも何度もありました。リリースしたあとで、統計情報のような、自分では細かくチェックしていなかった部分が、ちゃんと動いていた、と気づくこともありました。それくらいの量とスピードで進んでいた、ということでもあります。
作る機能が多く、さらに作り直しが数回
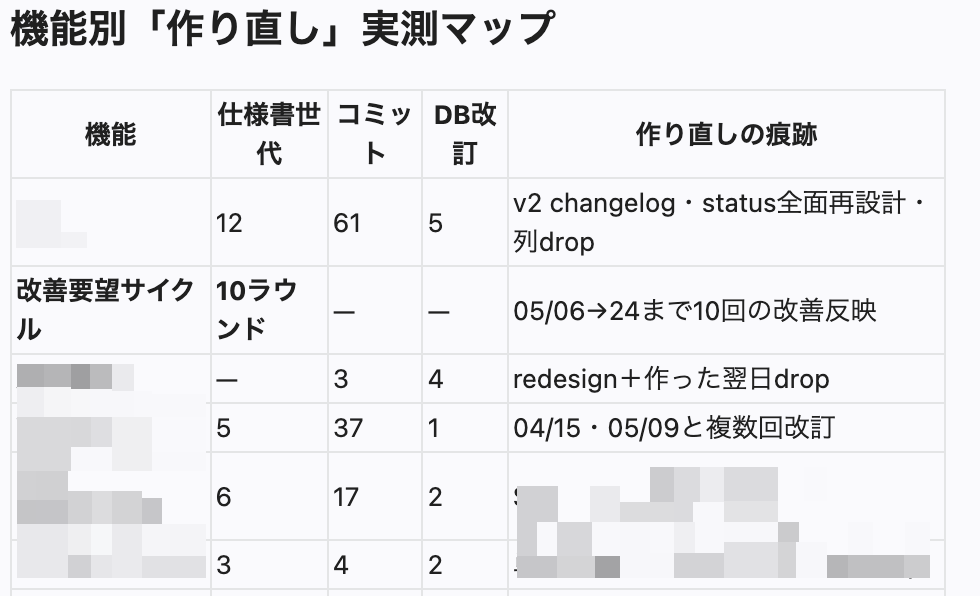
このMURAをAIなしの普通のやり方に換算すると、だいたい155〜180人月になります。gitの履歴とコードとドキュメントから積み上げた概算で、期間にして1年半から2年半、金額なら1.5億円くらいの規模です。それを、AI前提の実働でいうと8人月、カレンダーで約3ヶ月で出しました。
この155人月が何でできているかというと、まず単純に、作ったものの量が多いです。基本的なコミュニティ機能に加え、複数系統の決済、ゲーミフィケーション、メンバーシップ、バッジ、モデレーション、ノート、物販と配送、ユーザー面と管理面、統計情報など。ひとつずつがイチ機能として重く、それが何本もあります。
その量の上に、さらに土台からの作り直しが複数回あります。特に作り直しが多かったのは、物販まわりと、バッジまわりでした。物販まわりは、コミュニティのUXとしての流れや体験が重要になってくるので、企画の練り直しに追従するように7回くらい作り直した覚えがあります。一つの機能ではなく、全ての機能が有機的に連携できる形で毎回作り直しました。
VIPやギフト、カスタム絵文字をどう持たせるか、そのたびに組み替えました。バッジは、たとえば権限をフラグで持つかバッジで持つか、というところも細かく影響しています。途中で、殿堂ポイントという概念をやめて、VIPランクに作り変えたときは、コードの273箇所に影響が出ました。コミットの9割以上が、既存コードの書き換えを伴っています。
定例で話し合った内容を、明日、ブラウザで確認できるようにする。破壊的な変更を伴うものでも、そういう世界観で初期〜中盤では行っていました。ブラウザ確認をすると、机上では成り立っていた話が、形になると全然思っていたものが違ったり、新しいアイデアが出てくることはよくあります。この朝令暮改のような世界観を構築することで、判断までの時間を圧倒的に短くして、次の改善や機能追加にすぐさまつなげることができるようになります。
従来のやり方だと、ここまでの作り直しには予算もスケジュールもつかないと思いますし、どうしても2、3回で妥協するしかありません。AIがこのゲームを変えたのは、作る速度だけではなく、量をこなした上で、何度も壊して組み直せる回数の方も大きいです。
手を速くするのは、判断に時間をまわすため
それでは速く開発する工夫を書いていきます。
僕は、VSCodeを4つのペインに分けて(縦に4分割)、AIエージェントを並行で走らせていました。それぞれが担当する範囲をわけて、お互いのコミットがかぶらないように進めます。僕にとって開発画面とは、この4ペインのチャット欄のことです。
使うAIモデルやエディタは、その時期によって変えていました。Cursorをメインにする時期もあれば、Claude Codeをメインにする時期もあります。全部を同時に、という使い方ではなく、調子のいいものをメインにしていく感じです。
Antigravity+Gemini Proがデザイン系で強いとわかれば、そこだけ使うときもありました。
Codexは、4つのペインで動かすやり方がわからなかったので、ほかのモデルやエディタの調子が悪いときの、緊急避難先として使っていました。モデルも日によって出来不出来があるので、ひとつに固定していませんでした。
特に、Claude系の新しいモデルが出たらすぐに試して、良し悪し差分を一通り味わうようにしています。AI筋トレとでもいいますか、Xのレビューや周りが言っていることに惑わされることなく、普段から自分でやってみること。使い所やクセを体感することは、AIの能力を見極める意味でも大切にしています。
ただ、手数を増やすことやモデルの判別すること自体は目的ではありません。実装短縮で削った時間を、判断の時間にまわすためです。僕がやったことは、この判断をすぐ下せる状態をつくることと、その判断を待たせないこと、この二つに集約されます。
寝ているあいだに実装して、起きているあいだに判断する
人間には、AIとは違う制約があります。その制約が何かは、人によって考えは違うものではあると思うのですが、ただ、共通しているものがひとつあって、それは寝る時間です。人間、ここを0にはできません。AIは24時間、人は寝る制約有り、この制約をうまく使えないか、と。
そこで思いついたのが、寝る前に、直したい項目を書き出して、「これから寝るので、やっておいてください。1つずつ丁寧に、タスクに分けてかまいません」と投げて、AIに長い時間うごいてもらいます。そうすると、朝起きたらある程度できている。さらに長時間稼働を前提としているので、反復チェックでミスが少なくなっていました。
寝ているあいだに実装が進み、起きているあいだは判断とやり取りに使う。この非同期で、一日に進む量がだいぶ変わりました。AIに自分の状況を伝えることが、意外にもAIを使った開発においても大事だったりしたのです。
モデルは、人が判断しやすい方を選ぶ
OpusとCodex、Aモデルが良いかBモデルが良いか、とよく聞かれます。
僕は、判断が早く進む方を選びます。冒頭から何度かお伝えしているように、判断の早さには二つあって、ひとつは、判断までに行き着くモノができあがるまでの速さ。もうひとつは、AIの返答を人間が判断しやすいかどうか。モノができあがるまで速いに越したことはないのですが、僕はほとんどの場面で、人間が判断しやすい後者を基準に選んでいました。出てきたモノを自分がすぐ判断できるほうが、結局は速いからです。
ついでに、やっていないことも書きます。プランモードを意識的に設定してから始める、ということはしていません。
流れの中で計画を立てることはあっても、最初にモードを構える、はやりませんでした。Skillのようなものも、先に用意していません。先に技を設定しても、モデルが進化すれば古くなりますし、本当はもっと別のことをやるべき場面で、その技の使いどころを研究することに時間を取られかねない。そのため、素の状態、生のまま進めて、やっているうちに自然とメモリに溜まっていくのに任せています。
AIは大型新人、ガードよりもオンボーディングを厚く
僕は、AIのことを大型新人だと思っています。いますぐ成果をあげたい、能力がずば抜けて高い、どの職場にもひとりはいる期待感のあるあの人です。
少しの材料とやりたいことを渡すと、やったるぜ、という感じでやってくれます。もちろん成果を上げたくて、焦って最初は勢いよく間違えることは多いでしょう。間違えた場合は、オンボーディングが足りない、社内用語を誤解していたり、必要な情報が不足していたとか、人間を採用した後のクイックウィンにつなげることとだいたい似ていて、マネジメント側に工夫の余地があると僕は思います。
仕事ができるといっても、新人なのだから、自分や組織との相性が合わせる部分は丁寧に、それでもガードはひきすぎず、活躍の場を与える、そんなイメージで捉えています。
強いモデル(fable5)が来たら、まず判断の材料を取りに行く
fable5が数日だけ使えたことがありましたよね。期間限定の定額で使えるようになっていましたが、そのモデルの評価が済んですぐ、僕がやらせたのは、コードを書かせることではありませんでした。このサイトのセキュリティリスクと、リファクタすべき項目、それと全部ゼロから作り直すとしたらどうやるかを、ドキュメントにまとめさせることでした。なんとなく、このモデルはすぐ使えなくなる気がしていたからです。
実際、数日後に使えなくなりました。強いモデルが手元にある短い時間にやるべきなのは、目の前のコードを速く書かせることではなく、後から長く使える判断の材料を残しておくことでした。
移動中も、開発を止めない
移動中も開発を続けていました。
macbookで sudo pmset -a disablesleep 1 を叩くと、蓋を閉じてもスリープせず、wifiもAIのセッションも続きます。移動をする場合には、まずwifiをスマホのテザリングに切り替え、やってほしい作業を書き出して、AIに投下。これで、macを閉じて自転車での移動中も開発を続けられます。
場合によっては、セッションをスマホから引き継げるようにしておく。そうすると、指示が手元のスマホからできるようになるので、バス待ちの時間でも開発を続けられます。
ちなみに、もとに戻す際は sudo pmset -a disablesleep 0 です。
できるだけローカルでやる
クラウド型のAI、githubのissueを読み取りプルリクを投げておく、みたいなタイプを僕はほとんど使いません。基本はローカルです。
理由は、これも判断までの時間です。クラウドだと、ブラウザで確認するのにデプロイが要ります。CIなどもあって、コードができてから確認できるまで、1回10分ということがざらにあります。手元にもってくるとしても通信が発生します。
ローカルなら1回1秒です。この差が、そのまま生産性の差になります。だから僕はほとんどをローカルでやりますし、企画の人にも、できるだけローカルでのやり方を伝えるようにしています。
AIが止まっている時間の使い方
AIは、わりとよく止まりますよね。さっきまで動いていたのに、突然無限に出力したり、500 error、なんかわかんないけど途中で止まっちゃう。エラーになることはよくあります。しかも予兆があって、新しいモデルが出るという噂が流れている時と、月末あたりは、エラーになりがちです。
止まっている時は、無理に実装を進めません。確認作業を進めたり、改善する項目をまとめたり、手を別のところにまわします。どうしても実装したい時だけ、別のモデルに切り替えます。止まっている時間を、判断や整理、コミュニケーションの時間に振り替えるイメージです。
判断に必要な情報を、すぐ揃える
要望は、企画もエンジニアもGoogleスプレッドシートに書きます。これはあくまでリリース前の処置としてこの運用を行いました。判断するには、まず全体が見えている必要があります。
リリース前の方がリリース後よりも改善項目が圧倒的に多いのが世の常です。今回はそもそも作り変えているし、想定していない動作や、UXの設計の見直し、画面で見たら思ってたのと違うなんて当たり前なので、それを吸収できるかどうかが組織としての力量だと思っています。
issueでなく、スプシで時系列に残す
改善項目のスプレッドシートを、HTMLごとダウンロードして時系列で残しました。日付ごとのスナップショットが並ぶので、どこをやって、何が進んで、どう確認が取れたかが、日単位で分かります。GitHubのissueではなくスプシにしたのは、この網羅性のためです。
1件1チケットのissueだと、全体の中で今どこにいるのかが見えにくいですよね。この段階では、一覧で全体が一度に見えるスプシの方が目的に合っていました。さらに、Slackでのやり取りもドキュメントに入れて、スプシに載っていない補足や、説明の足りない所を埋めました。これで、仕様が途中で動いても耐えられる運用になりました。(slackをmcpにしていないのは後述)
AIで、コードと全項目を照合する
htmlでダウンロードしたシートをdocsディレクトリとして保存し、それをAIに渡します。渡すときには実際のコードと1項目ずつ突き合わせをしていき、この要望は今のコードでどうなっているか、実装済みか、バグか、未実装か判断し、あとは上から潰します。これを25日間で13回まわしました。この中には破壊的な変更は多く含まれます。毎日、増え続ける改善項目を、だいたい2日に1回の頻度で総なめして実装していました。(改善項目を確認する側も非常に大変だったと思います。)
AIに渡す時の小技があり、改善要望_20260415.htmlなんて名前をつければ、それがその日の改善要望だということが明示的にわかり、そして次の日には改善要望_20260416.htmlをつくることになるので、その差分をコード上で取ったりすると進捗がより鮮明になっていきます。
25日間で13回まわした、要望の処理サイクル。
優先順位づけは、実装フェーズでは要らなくなった
このスプシ集約で全体を見通せる判断のほかに、副次的に気づいた点があります。本来だったら改善においては優先順位付けを行い、例えば優先順位でA〜Dがあった場合、Aを集中してやってBはできればやる、CとDはリリース後といった運用になると思います。
今回のスプシとAIを使った実装はA〜Dは並列に作業が進み、人への改善要望そのものがAIへの指示書になっていて、優先順位付けは実装フェーズではいらなくなったことがわかってきました。もちろんその後の、人が画面で確認する部分に多くの時間がさかれるので、優先順位付けは実装順ではなく、人が確認と判断をする順番となっていたと思います。
自動化せず、目視をはさんだ理由
このスプシとAIを自動でつなぎ実装する仕組み、claude-code-action、Bugbot、MCP、SKILL、ワークフロー、 GAS、手段はいくらかあると思いますが、僕はあえて自動化しませんでした。理由は二つあります。
ひとつは、やり取りを時系列の記録としてドキュメントに残したかったこと。ダウンロードしたファイルが日付ごとに積み上がる形の方が、後から追いやすかったです。
もうひとつは、ダウンロード前に目視することで、AIを操作する僕が目視でシートをひととおり眺められるようにしたことです。眺めると、何を先にやるべきかが見えてきます。これが判断の速さに繋がっていきます。全部を自動化にしたり、それを目指そうとする過程で、自動化することが目的になりかねません。
明日には旧モデルになりかねないAIの自動化に邁進するより、眺めることに時間を使い、それにより判断を速くなるのであれば、生産性が高いと僕は考えています。
判断そのものを、速くする
どこが律速か
ここでいう律速というのは、進行上どの部分が一番遅くなるか。僕はボトルネックと微妙に使い分けていまして、ボトルネックは全体進行が窮屈に遅くなるイメージ、律速は全体的に進んでいるけど一番遅くなり得る部分のイメージで使っています。
そのとき大事なのは、AIで工数が大きく縮む所と、縮まない所を、先に見切ることです。大きく縮まないところが律速となります。
| 大きく縮む | 縮まない(人が決める) |
|---|---|
| 実装そのもの、作り直し | 関係者とのすり合わせ |
| 大量の要望とコードの照合 | 隠れ機能を掘り起こす、決める判断 |
| 枝葉の試行錯誤 | UX、文言、伝え方や表現など |
| ライブラリの選定 | 仕様変更に伴う法務確認 |
そして、縮まない所、つまり構造や中心になる概念は、できるだけ先に決めきってしまいます。ここを後から変えると、影響が一気に広がるからです。僕はMURAで「殿堂ポイント」を「VIPランク」に作り変えたとき、273箇所の手戻りを出しました。先に決めきれていれば防げた手戻りで、正直に言えば反省点です。
将来のAIに後まわし
リリース前も、リリース後も、技術的にやりたいことは山ほど出てきます。どのサービスも、あそこが気になる、ここが気になるというのは必ずと言っていいほどあるはずです。何度も仕様を変え、毎日、膨大な実装と確認を行っているならなおさらです。
従来であればどこか時間とお金をかけてきれいに整えていくフェーズでも、今回は、将来のAIに賭ける選択をしました。先程のAIの工数が大きく縮む表の部分において、将来のAIではより得意になっているのであれば、今あえて時間をかけることはしなくて良いと思っています。
言葉の整理
ただ、いち早く先に整理した方が良いと思うのが、ひとつだけあります。それは、言葉の整理です。たとえば「通知」という言葉。ある人にとってはメールのことで、別の人にとってはサービス内の新着のことだったりして、人によって指すものが違います。
こういう曖昧な言葉が残っていると、人間も迷うし、当然AIも迷います。コミュニケーションロス、仕様の誤解、これはAIでも発生します。あいまいさを減らすことは、判断の迷いを消すことなので、ここは後まわしにしませんでした。
一度、変数の名前のレベルまで踏み込んで、言葉の意味をそろえた時には、この整理のためにcursor+opus4.8にて1回で1.5億トークン、7000円分を使っています。7000円で、その後の生産性に倍速になるのなら安いものです。
1プルリクに詰め込むことを許容する
機能ごとにきれいにブランチを分けて、1機能1プルリクにするのが良いやり方です。でも、AIが何本も並行で作っていて、作り込みのフェーズでは、細かく粒度を区切ることにあまり意味がありません。
たとえば「投稿」という機能をひとつ作るだけでも、マイページ、画像アップロード、その管理画面、NGワードと、関連する機能が次々くっついてきます。AIが作っているのを眺めているあいだに、あれも欲しい、これも直したい、と出てきます。そのたびにブランチを切り直してAIが終わるのを待っていたら、自分で生産性を落としているようなものです。こういう時は、思い切って1本のブランチに詰め込みます。worktreeでコンフリクトを解消するくらいなら、最初から1本にまとめておく。
僕がつめこんだプルリクの例として、消費税の外税対応+配送シートの修正+アイコンの設定+絵文字の統一+ドキュメント整備+DB修正があります。それぞれが内容として独立しているのですが、4ペインの並列で動かしているので、むしろ独立していた方が都合が良いのです。
ブランチ名やプルリクの整理が大事なのはもちろんわかっています。でも、この時のフェーズとして意識していたのは、判断までの待ち時間をつくらないこと。1日でも速く確認ができれば、チームに自信と強さが生まれ、ユーザーのみなさまにもより良いものがすばやく提供できます。
プルリクには、詰め込んだ内容や意図を、タイトルと説明文にAIで整理して記載しておけば、後からでも確認や整理ができるし、それをAIに書いてもらったり整理してもらえばいいはずです。
手戻りよりも突き進む方を選択
1プルリクに詰め込む方法で気になることとしては、1度マージしたものをもとに戻したくなったときです。これはAIの進化が解決してくれました。
2026年2月に登場したOpus4.6、このモデルがゲームチェンジをしていて、それまでのAIは実装したら別の機能が壊れやすく、間違えたら戻す手法を僕はとっていました。しかし、この手法から、Opus4.6以降では壊れたらそのまま突き進んでも直しきれるようになったと僕は感じています。
判断を、待たせない
プロジェクトの終盤、僕は実装そのものをすることはあまりしなくなっていました。企画メンバーが、ローカルでAIを使って自分でコードを書き、プルリクを投げられるように整備されたからです。僕の思いつきを三浦さんがキャッチ、やり方はチームで相談し、メンバーが整備してうまくハマったと思います。くじページの作り直し、ミッションの挙動、チャンネルのUI、利用規約のページまで。さらにgithub側に導入したAIのレビューがそのプルリクに指摘を入れています。
プルリクをレビューする時において、僕はその時、プルリクを出してきた本人にこれで合ってますかをほとんど聞きませんでした。僕はコードも読んでいません。プルリクに対してローカルのAIにURLをはり、何を意図して、差分は何で、マージしたらどういう機能が加わり、そしてそのリスクはなにか、こういうふうに聞けばその人が何をやりたいか、どこを修正しないとマージできないか示唆としてわかります。
従来の開発だと、ここに往復がはさまります。仕様を書いて、レビューで質問して、返事を待って、直してもらって、また見る。1往復で半日、込み入った話なら1日かかります。その待ち時間が、機能の数だけ積み上がります。確認の往復を減らすことは、判断までの時間を減らすことに直結します。
経営層が、開発の中を直接見られるようにした
組織の側で示唆したことも、もうひとつ書きます。経営層やプロジェクトマネジメントの層が、githubを自分のPCから具体的な内容をAIを経由して参照できるようにしました。
これは、僕がチームにこうすると中が見えると示唆して、メンバーが実際に整えてくれたものです。誰が今どの部分に取り組んでいて、いつ何をやったか、そしてそれが、AIがなかった時代と比べてどのくらいの量なのかが、見えるようになります。
エンジニアが何をやっているのかわからない、というのはよくある話です。そこを、githubとAIを経由して見えるように、組織の見通しをどの角度からでも見れるようにしました。中身のコードが読めなくても、何がどれだけ進んでいるかは、AIに要約させれば把握できます。経営層がそれを見られると、次に誰へ何を任せるか、どこを足すか、という采配が速くなります。これも、判断の時間を短くする話の一部です。
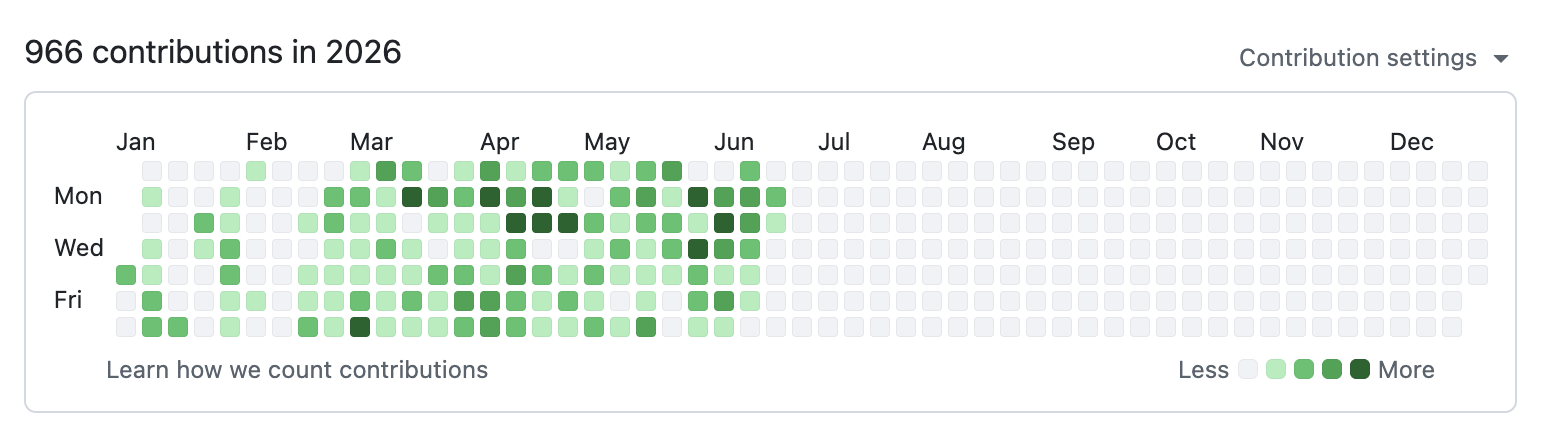
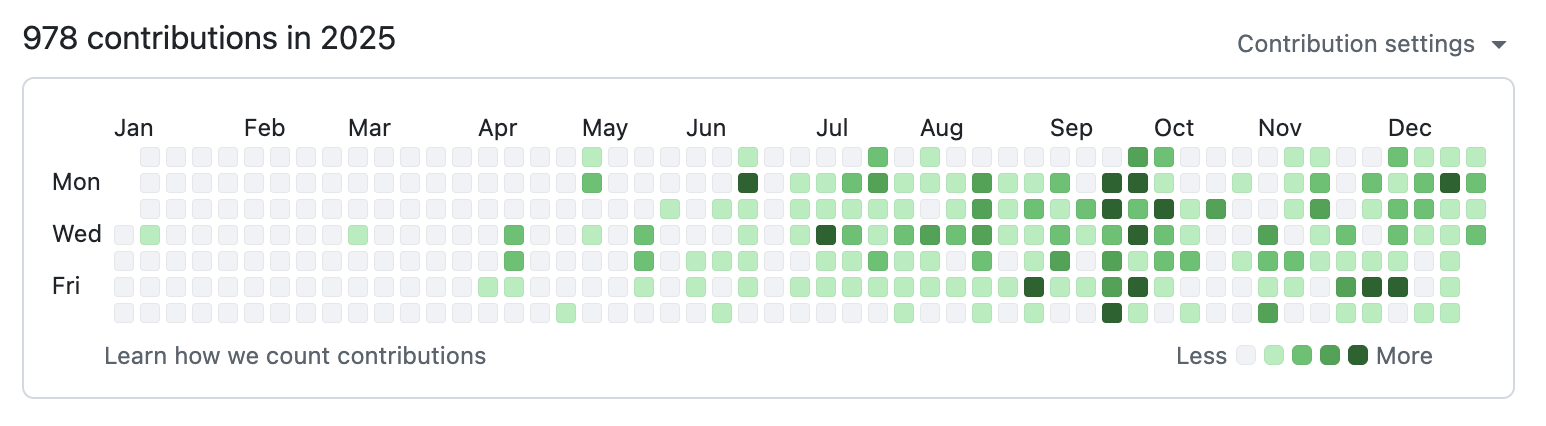
AIをつかった開発の見える化には、少しポイントがあります。コミットの数や、コミットメッセージの文章は、いくらでも盛れてしまいます。数を稼ぐことも、それらしい文章を書くこともできるからです。そのため、数や文章ではなく、実際にマージされたプルリクに含まれる実際に変わったコードです。
何が、どれだけ、どのくらいの難しさで変わったか。そこをAIに読ませることで、エンジニアでない人にも、本当の生産性が見えてきます。
前衛、後衛、企画。AIは得意に倍率をかける
ここまでは主に僕ひとりの動き方の話ですが、チームでやるときに大事だと思っていることも書きます。AIは、能力の乗算です。ドラゴンボールでいう界王拳です。得意なところに倍率をかけると、もとの能力が大きいほど倍率がかかるので突き抜けて大きな能力になります。そのため、自分やメンバーが何を得意とするかを、きちんと見極める必要があります。
役割は三つ
役割は、ざっくり三つに分かれます。企画、つまりやりたいことを決める層。前衛、僕のように、ガンガン作っていく層。後衛、技術的に細かくチェックする層。前衛がどんどん作るなら、確認と判断は誰かに任せたい。そこを後衛がカバーします。
僕が企画者のプルリクを本人に確認せずにマージしていたのは、前衛としての心持ちがあるからできることだと思っています。
任せ方を間違えると
前衛に後衛をやらせると、細かい確認が膨らんで穴だらけになりがちです。逆に、後衛に前衛をやらせると、できる選択肢の中から選ぶ動きになって、細かいチェックも通したくなるので、これもフィットしません。後衛が得意な人には後衛を、前衛が得意な人には前衛を。AI倍率がかかるぶん、20×10で200になるか、2×10で20になるか、この差が生産性に直結します。
後衛がいちばんシビア
誤解されがちですが、後衛は受け身のポジションではありません。ユーザーや事業にとって何が必要かを、いちばんシビアに考える位置です。前衛や企画の気持ちがわかる人が、ここで効いてきます。
後衛にありがちなのは、こうじゃなきゃいけないと言って止めてしまうこと。これは、聞いている側からすると意思決定に迷う原因になります。立ち止まって欲しいときは、それが今すぐ必須の原則なのか、それとも推奨なのかを、セットで伝える必要があります。技術的な妥当性を含めて判断して伝えていくので、本来、開発においては一番難しいポジションだと思っています。
パンでいうと
イメージでいうと、前衛はうまいパンをこねる人で、後衛はそのパンに何か混入していないかを判断する人です。こね方のセオリーや、売り場の並べ方、レジまわりは最悪どうにかなると二人とも思っていて、手がまわったらやるくらいのバランス感覚です。
できる人に比重が寄るジレンマ
難しいのは、あるフェーズによっては、できる人に比重がすごく重くかかることがAI開発においても発生します。得意に合わせたAIの倍率のかけ方をすると、自然とそうなってしまいます。
組織としては、本当は和らげたほうがいいのでしょう。多少のリスクとジレンマは、抱えることになります。ここへの答えは、今のところ思いついていませんが、20×10を6×10でもなんとかやっていけるくらいの組織の弾力性は、AI時代においても必要になってくるかもしれません。
結局、何をするか
AIを使ったチーム開発で生産性を上げるというのは、各自のAIに界王拳をかけて、何倍にもなった状態で、まっすぐに一直線に判断までの時間と判断そのものの時間を短くしていくことだと、今は思っています。誰かのポジションを誰かがかわる、という話ではないように思います。
企画する人が、自分で作る側にまわれるか
企画者が、ローカル開発環境やgitに慣れていないのは当然です。でも、かつてはパワポも表計算も、当たり前ではなかった時代には、越えなければいけない壁でした。
今の大学生は、AIを当たり前に使って、企画したら自分で作るところまでがセットになっていくでしょう。つまり、これがいずれ普通になると予想がつきます。とはいえ、この壁を越えるのは本当に大変だと思います。
このMURAのリリースまでの間、僕は他に4つのプロジェクトも並行で見ていました。企画の人や経営層が、それぞれ自分で作ることに挑戦しました。
多くは最初、一見できているように見えて、中身はばらばらでした。データが繋がっていなかったり、本番に反映するところで手こずったり、gitやキーの扱いに不慣れで、あと一山が越えられない。
それでも、そこから1ヶ月で兆しが見えて、2ヶ月で少しずつ本番化できています。
再現できること、できないこと
ここまでの話を、再現しやすい部分と再現しにくい部分にわけてまとめます。
| 再現しやすい(仕組み) | 再現しにくい(判断・文脈) |
|---|---|
| 要望をスプシに集めてAIでコードと照合して実装 | issueを捨てると決める判断 |
| 企画者がプルリクをなげられるように整備し、不慣れな部分の伴走 | 企画者がプルリクを投げることにGOを出す判断 |
| AIで縮む工数と縮まない工数を切り分ける見方 | 他の人のプルリクを、本人に確認せず意図だけで直せる文脈 |
| ペイン分けしてAIを並行で走らせる体制 | その人の得意を見極める判断 |
組織にAIを実装するということ
AIの導入というと、ツールを配って研修をやる話になりがちです。でも、それだとプルリクは増えても、レビューやマージの所で渋滞します。実装者が増えるほど、そこを収束させる人がいないと事故が増えます。
僕らがやっているのは、ツールを入れることではなく、判断の時間を短くする運用ごと組み替えることです。判断に必要な情報をすぐ揃える入口と、その判断を待たせない出口。この二つを運用としてセットで組まないと、AIの倍率をかけて生産性の桁は変わりません。MURAでやったのも、エンジニアを加えることではなく、この作り方ごと入れ替えることでした。
この記事は、こういう会社に向いている
この記事に書かれたやり方は、こういう会社に向いていると思います。すでにAIツールは入れたのに、結局スピードが上がっていない会社。AIに数千万円を投資したのに生産性があがりきらない会社。どの点においても、開発の運用そのものを入れ替える方が、結局は早いです。
逆に、まず手元の業務をAIで少し速くしたいだけ、という段階なら、ここまでの作り替えは大げさかもしれません。その場合はツールの導入から始めるのがいいと思います。
自分の考えたことが形になっていく。やりたいことが、実現できていく。言うなれば、誰かのエゴを形にするのが、開発だと思っています。お手伝いできることがあれば、お声ください。X(@WAZGO)のDMが繋がりやすいです。
この記事では、再現できる型をまとめてきました。でも、明日には新しいAIが出て、新しいゲームが始まっているかもしれません。そうなれば、ここに書いた型も、もう再現性のない話になっています。
ただ、変わらないのはその時その状況で判断の時間をどう短くするかを考え続けることなのかもしれません。
このMURAの再構築について、企画統括の三浦慶介さんが書いた記事があります。本稿はその当事者(Y氏)側の記録です。
https://note.com/keisuke_miura/n/nb40f34aa5352
記事の文章そのものは僕が書いているのですが、この記事を集中して書くためのローカル用のエディタ(道具)もAIで作りました。ブラウザで見たまま書いてその場で保存できる、僕だけのとっておきの小さなローカルサービスです。開発にかかった時間は、ほんの数分です。
道具はAIで即席で用意して、言葉にするところは人間がやる。この道具のおかげで、ここまで集中して書き上げることができました。これそのものが、AIがもたらすメリットだと思っています。ここまで読んで頂いたあなたもいま、その恩恵を受け取っているわけです。